Interactive 4D Visualization
Explore the 4D reconstruction results of St4RTrack on various dynamic scenes. Please visit interactive results for more examples.
(Results are downsampled 4 times for efficient online rendering)
Explore the 4D reconstruction results of St4RTrack on various dynamic scenes. Please visit interactive results for more examples.
(Results are downsampled 4 times for efficient online rendering)
Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework.
Pointmap representation: estimate per-pixel xyz coordinates for two frames, aligned in the camera coordinate of first frame.
Key Insight: by repurposing the two pointmaps, we enable simultaneous tracking and reconstruction with the same architecture.
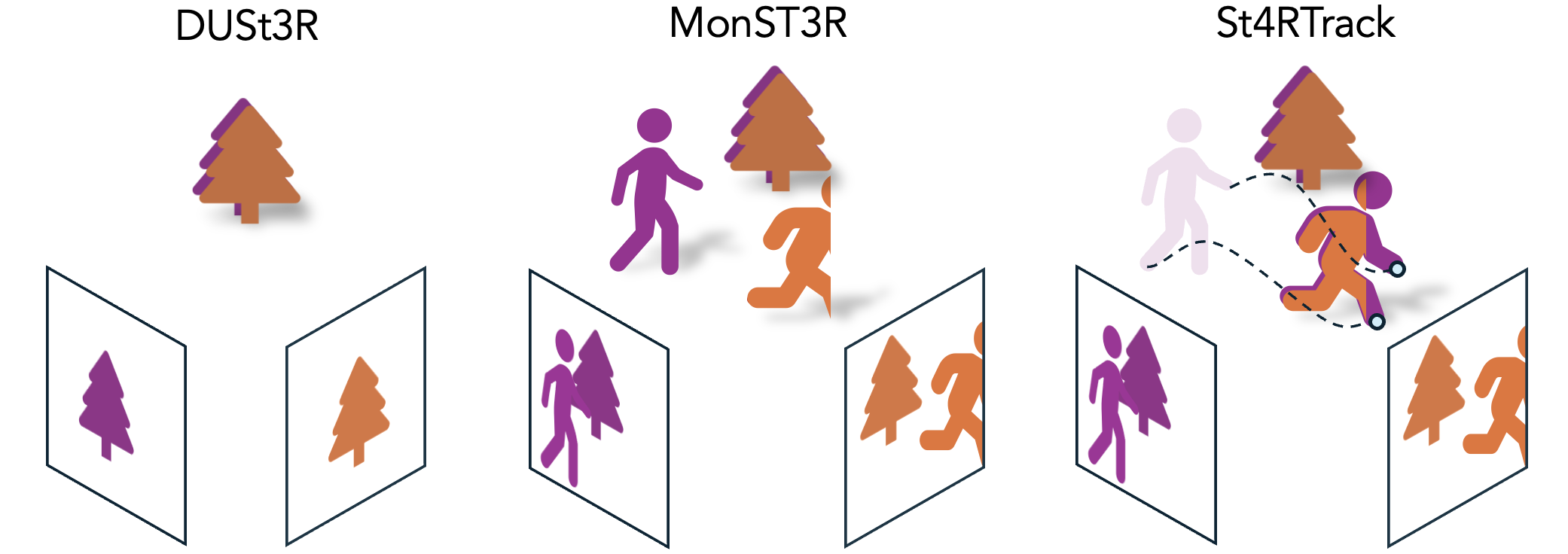
We train our network on three synthetic datasets and found that training on small-scale, sparse labeled, and unrealistic synthetic data is sufficient for our network to learn the newly proposed representation.
However, synthetic training alone limits generalization to real-world scenes with complex motion and geometry. We address this by leveraging the inherent geometric and motion in the representation to adapt to any video without 4D labels, using only reprojected supervision signals like 2D trajectories and monocular depth.
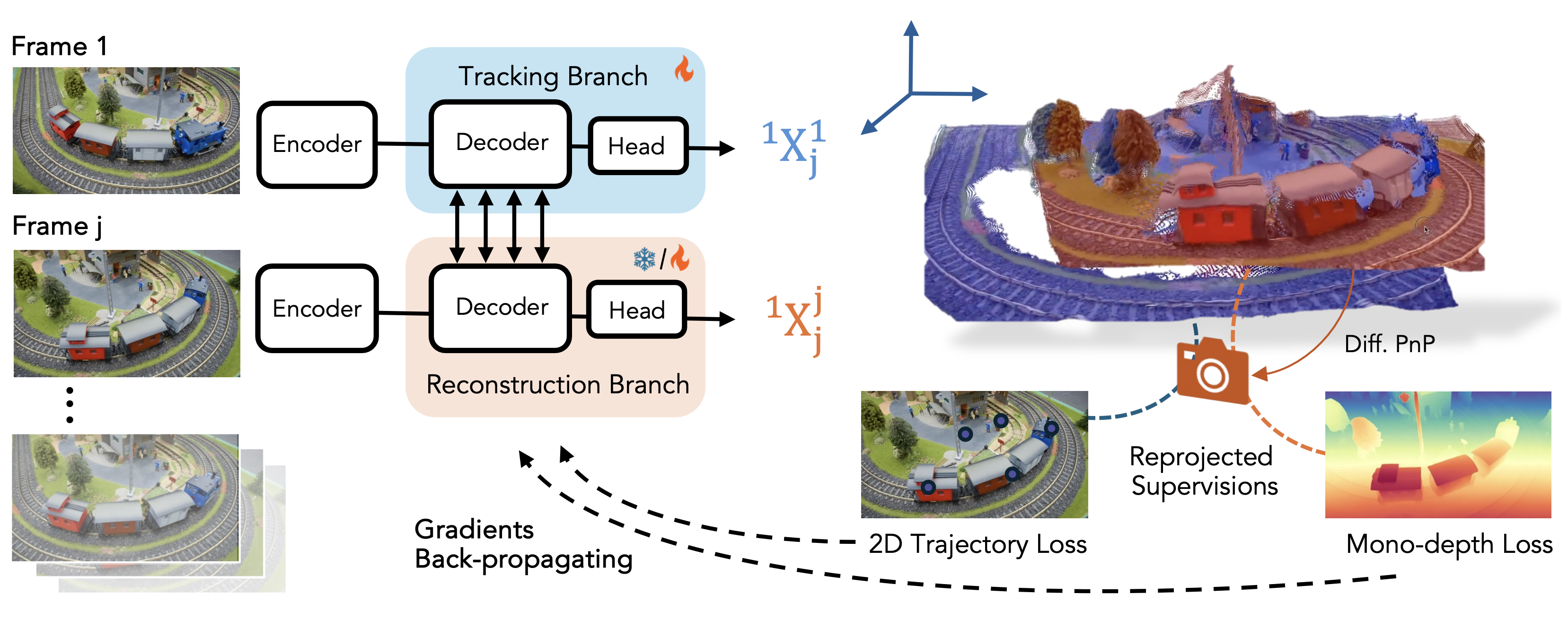
Since there is no previous work on world coordinate tracking, we first propose a new benchmark, WorldTrack, for evaluation.
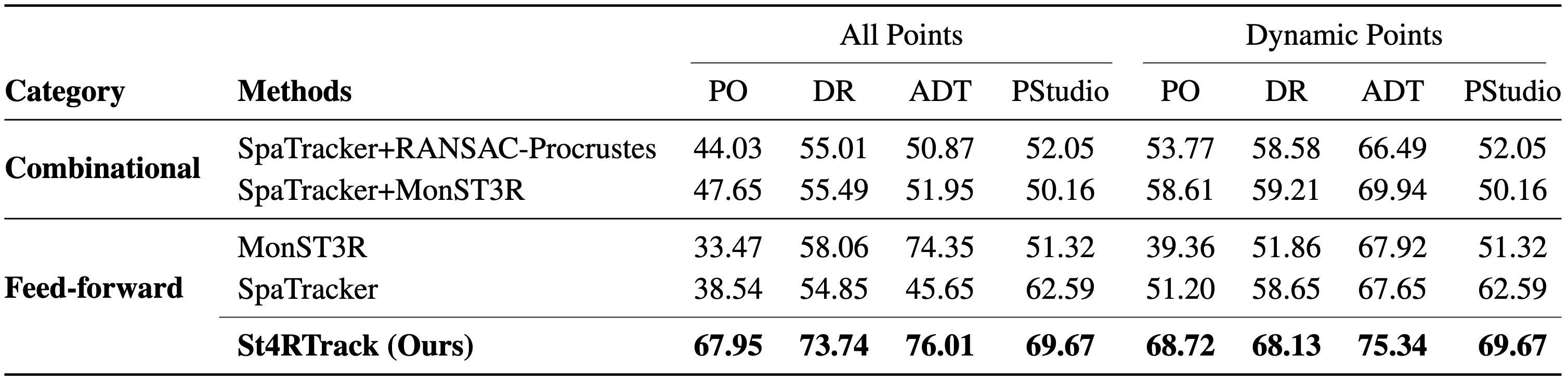
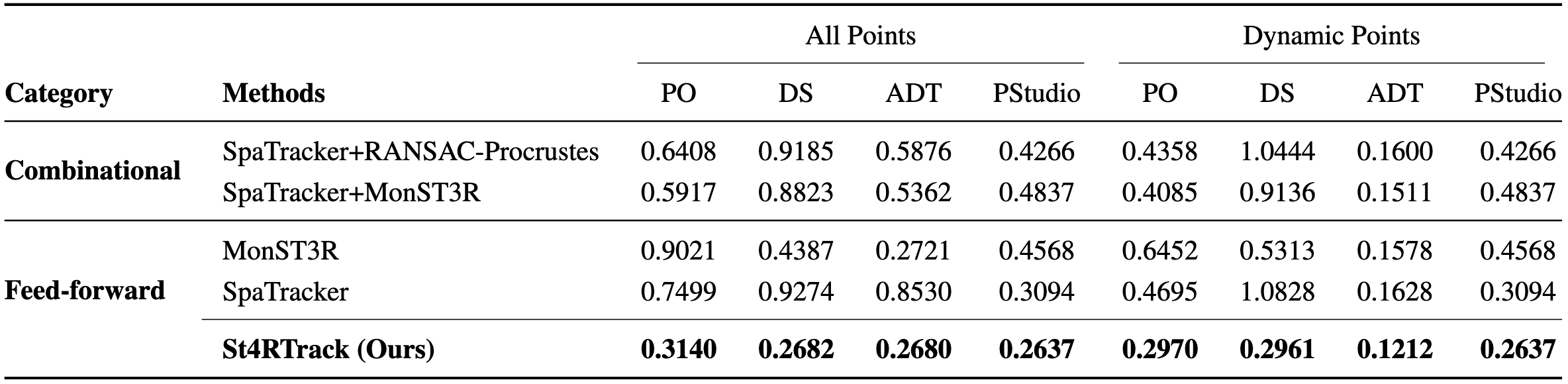
Qualitatively, St4RTrack achieves best APD (upper) and ATE (lower) on WorldTrack, compared with combinational methods.
Qualitatively, St4RTrack can handle both camera and scene motion, in a feed-forward manner.

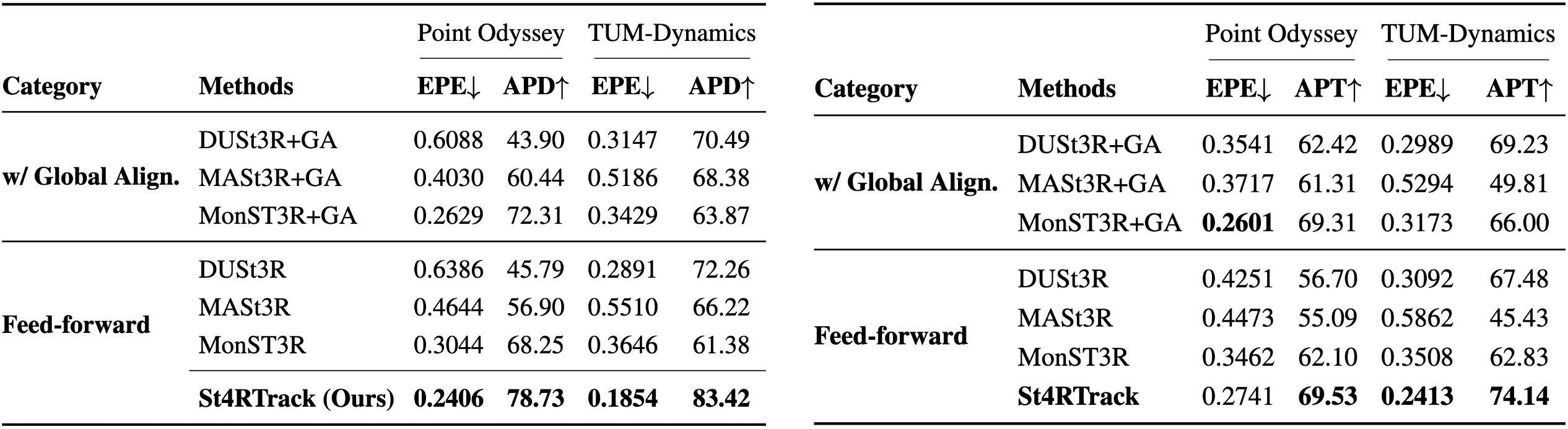
Quantitatively, the reconstruction results are competitive with task-specific methods.
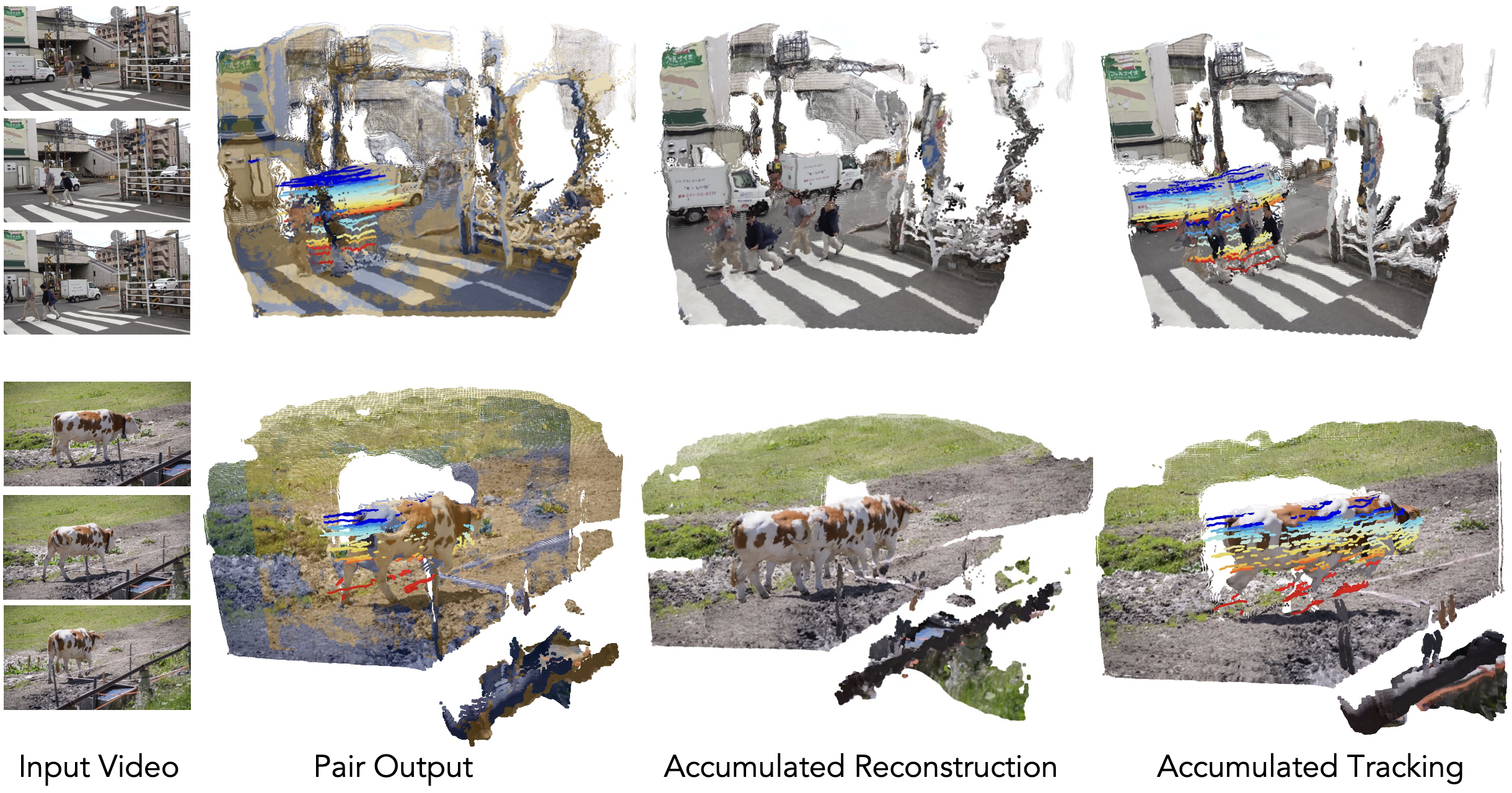
Qualitatively, St4RTrack achieves reasonable results as a pair-wise feed-forward framework.


We show below the pair output of a single frame, accumulated reconstruction, and accumulated tracking results on DAVIS.


Despite St4RTrack's promising approach to unified dynamic scene understanding, several limitations remain:
We believe large-scale pretraining, when compute permits, could boost St4RTrack's performance for complex, in-the-wild videos.
@inproceedings{st4rtrack2025,
title={St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World},
author={Feng*, Haiwen and Zhang*, Junyi and Wang, Qianqian and Ye, Yufei and Yu, Pengcheng and Black, Michael J. and Darrell, Trevor and Kanazawa, Angjoo},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2025}
}
Acknowledgements: We borrow this template from SD+DINO, which is originally from DreamBooth. The interactive 4D visualization is powered by Viser. We would like to thank Aleksander Holynski, Yifei Zhang, Chung Min Kim, Brent Yi, and Zehao Yu for helpful discussions. We sincerely thank Brent Yi for his support in setting up the online visualization. We especially thank Aleksander Holynski for his guidance and feedback.